Open WebUI and GPU Trader
Open WebUI is an open-source, browser-based interface for interacting with large language models (LLMs) like those running on Ollama, LM Studio, or local GGUF models. Designed for speed, simplicity, and privacy, Open WebUI offers a clean chat interface with support for multi-user access, prompt history, system prompts, and customizable personas. It runs entirely on your own hardware or containerized environment, ensuring full control over data and model execution. GPU Trader offers a pre-configured managed template to deploy Open WebUI in a single click—making it easy to run private, performant LLMs without needing cloud accounts or API keys.Install Open WebUI on GPU Trader
Sign Up and Create an Account
Start by signing in or creating an account on GPU Trader. If you need help, watch the GPU Trader Quickstart or read the docs.
Find and Rent a Compatible Instance
Use the Find a Device page to browse available GPUs. Filter by model, price, or provider to select a system that meets Open WebUI’s requirements.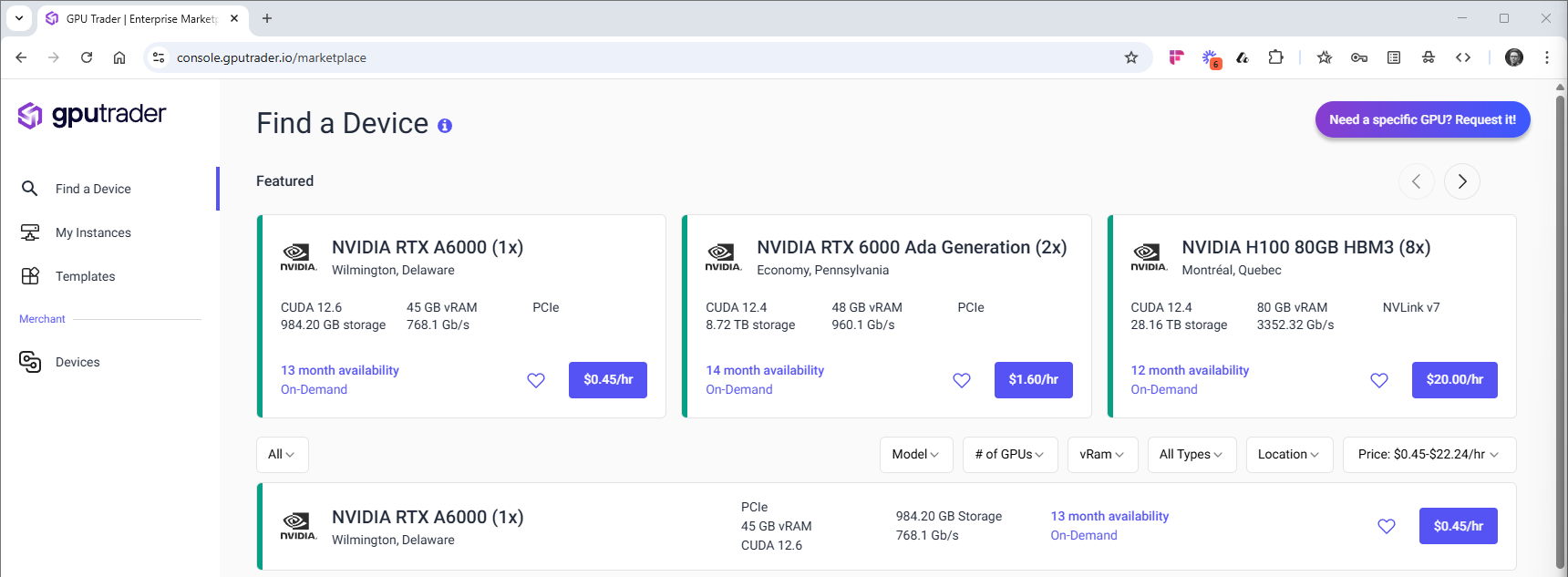
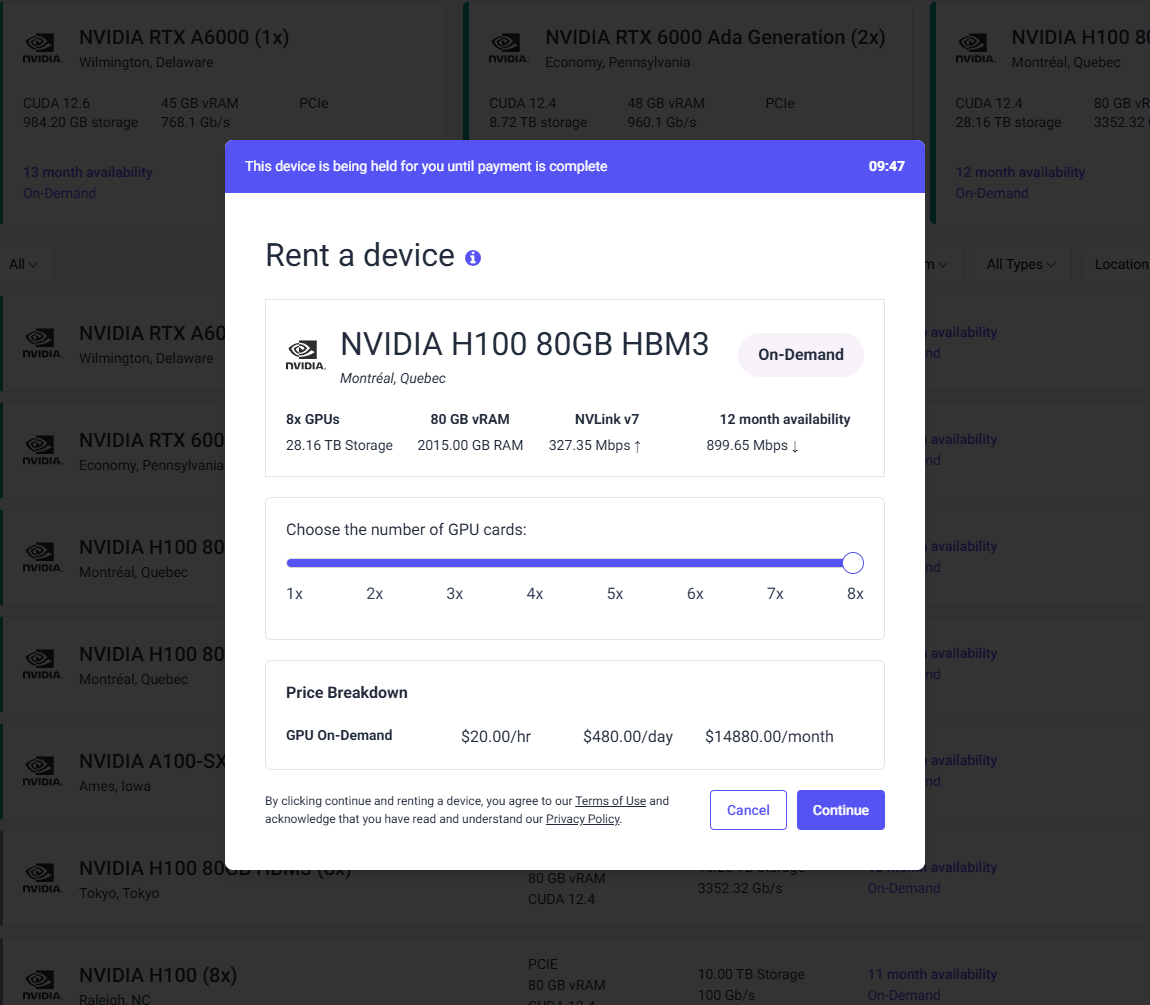
Configure Your Instance for Open WebUI
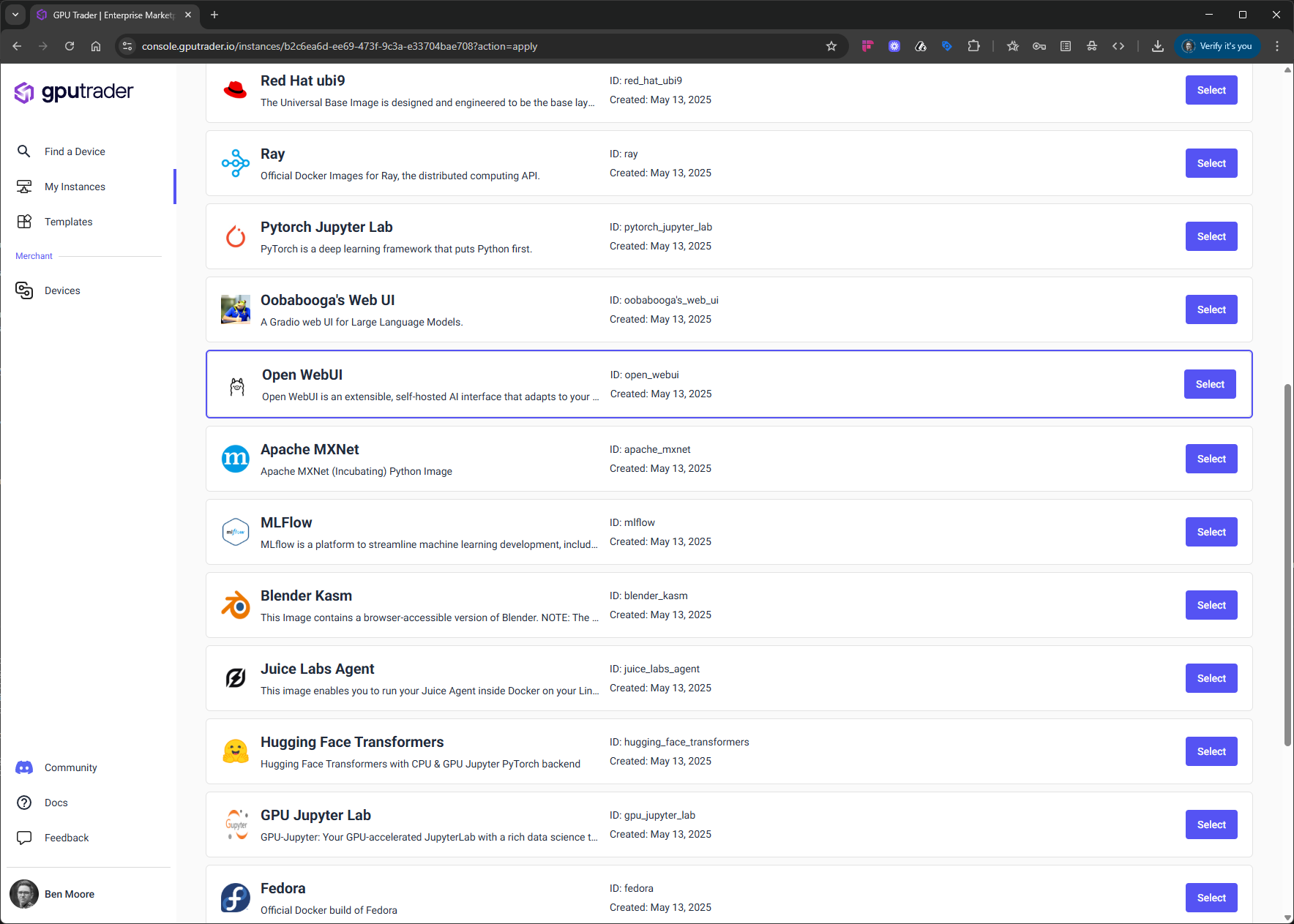
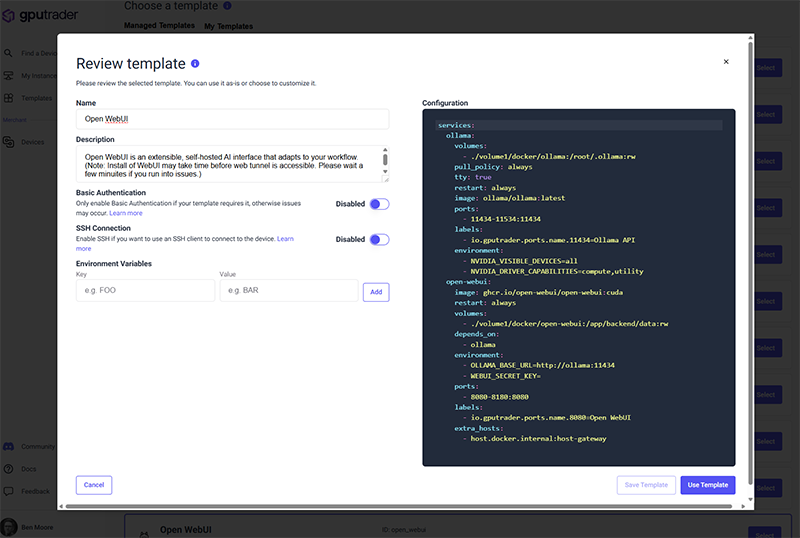
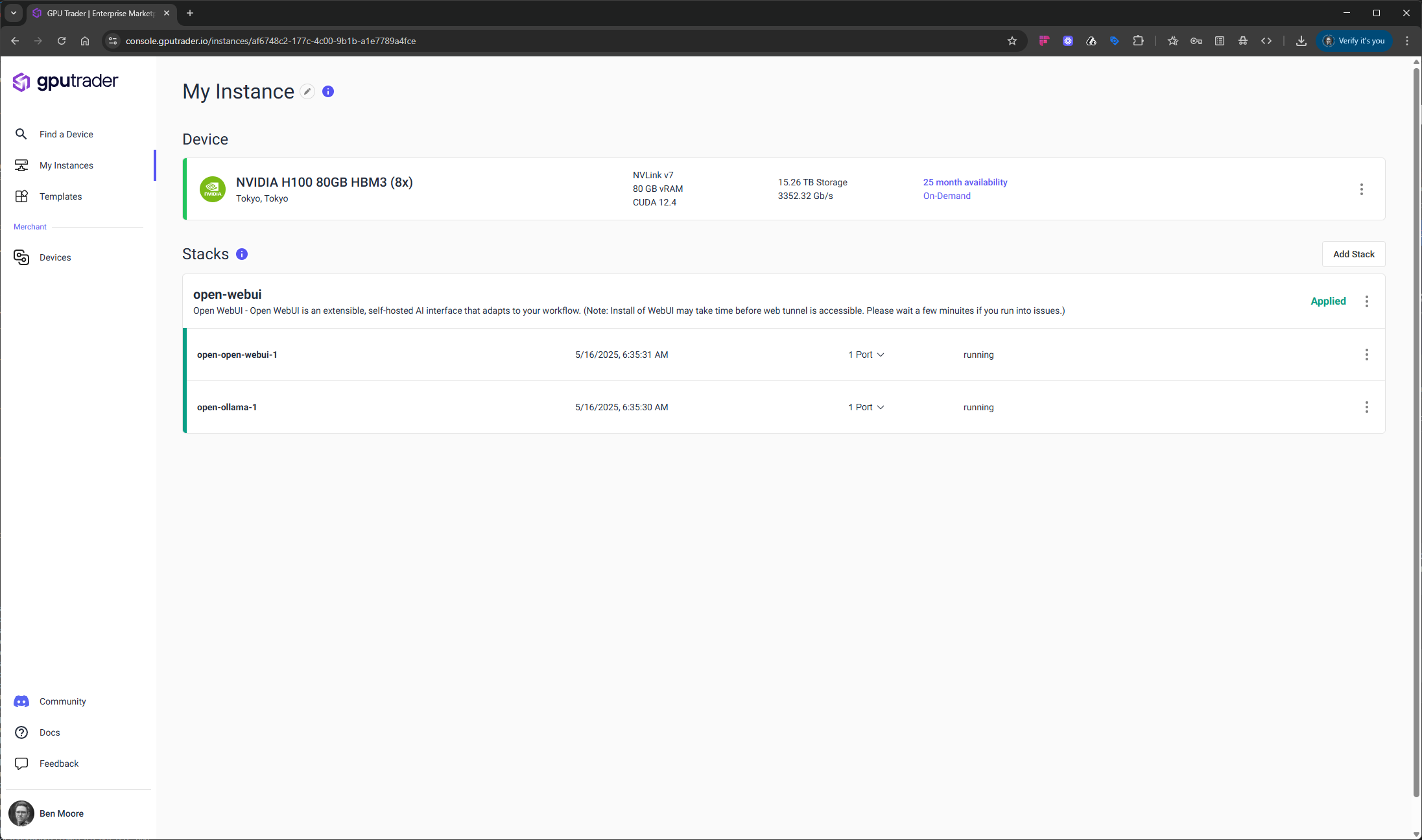
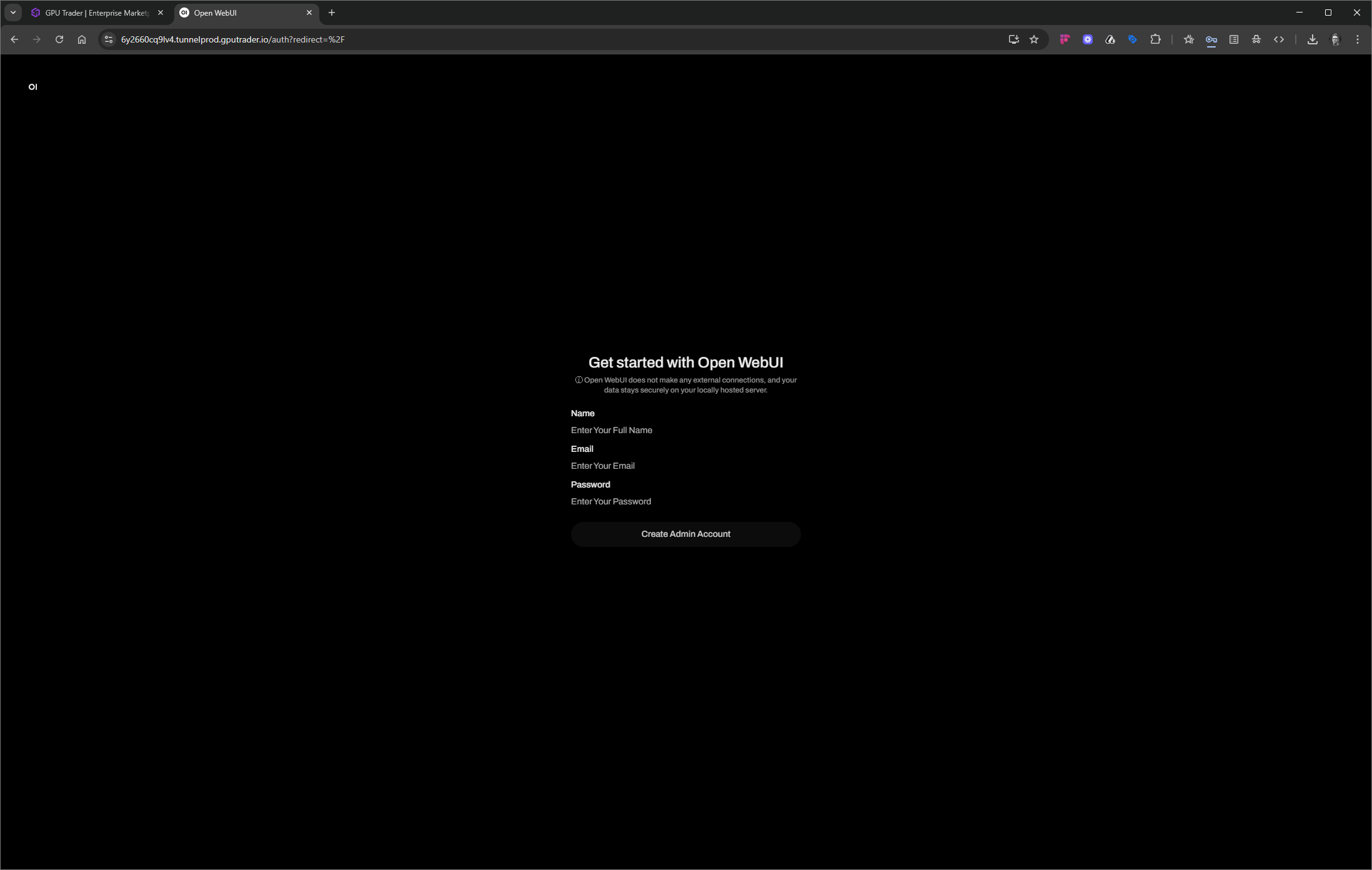
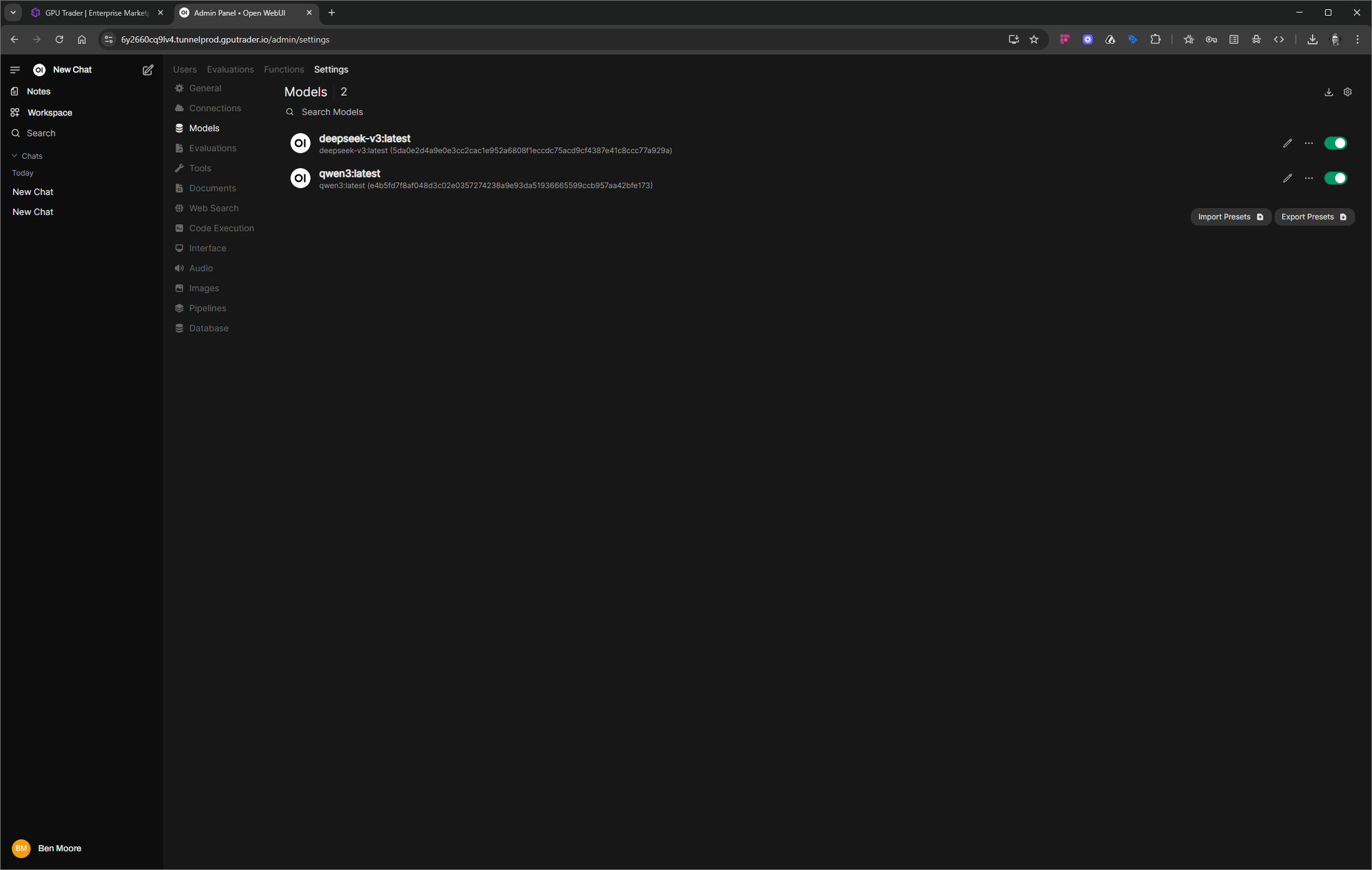
Get Started with Open WebUI
We will be the first to tell you, we are not experts in Open WebUI or the models that run on it, even though we think it is really useful and fun. If you are new to LLMs it is best to refer to the documentation for that model. To help you understand model compatibility we have created a list. The list is not comprehensive and should be used as a reference. There is good information on the web dedicated to optimizing the performance of your LLM.Model Compatibility
| LLM | Best For | Recommended GPU(s) | Notes |
|---|---|---|---|
| DeepSeek R1 | Logical reasoning, math, multilingual tasks | 2x A100 80GB or 1x H100 80GB | Efficient Mixture-of-Experts model; rivals GPT-4 in performance. |
| Qwen 2.5-72B | Coding, multilingual tasks, long-context understanding | 1x H100 80GB or 2x A100 80GB | Excels in coding and supports 128K context window. |
| Mistral 7B | Chatbots, summarization, lightweight applications | 1x A10 24GB or better | Fast and efficient; ideal for real-time applications. |
| Gemma 2 27B | Multilingual QA, RAG, fine-tuning | 1x A100 80GB or 2x A40 | Optimized for performance on NVIDIA GPUs; good for RAG pipelines. |
| LLaMA 3.3 70B | General-purpose reasoning, coding, assistant tasks | 2x A100 80GB or 1x H100 80GB | Strong all-rounder; extensive community support. |